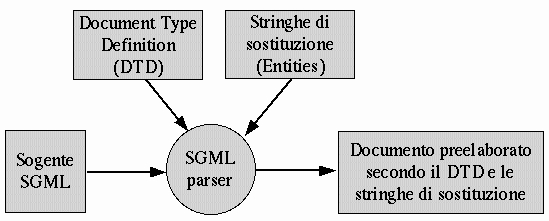
SGML sta per Standard Generalised Markup Language e si tratta di un linguaggio di markup che dovrebbe collocarsi al di sopra dei programmi normali di editoria. Il suo scopo č determinare le regole attraverso cui i vari elementi del testo possono essere utilizzati, e possibilmente, generare un risultato adatto alla successiva elaborazione da parte di altri programmi di composizione.
SGML si basa sull'uso di marcatori con una forma standardizzata del tipo <marcatore>, per iniziare qualcosa e </marcatore>, per concluderla. L'utilizzo di questi marcatori (tag) e le regole a cui questi sono sottoposti, viene definito all'interno del DTD (Document Type Definition). Questo č solitamente un file separato, ma puň anche fare parte del sorgente SGML stesso. In pratica, il DTD determina la ``sintassi'' che puň essere utilizzata e viene utilizzato per verificare la correttezza del sorgente SGML.
Per comprendere il senso di questo, si puň immaginare per esempio che non č possibile indicare un grassetto se prima non č stato definito il marcatore per il grassetto e non č stato definito l'ambito in cui questo puň essere utilizzato. Questo permette anche di capire che un analizzatore SGML non puň generare un documento finale, al massimo si limita a verificare la correttezza del sorgente in base a quanto indicato nel DTD. Sarŕ poi compito di un altro programma il trasformare opportunamente questo documento in qualcosa di stampabile.
SGML, oltre che stabilire la struttura di un documento, serve anche per predisporre delle macro con le quali č possibile fare riferimento a stringhe. Questo meccanismo permette in particolare di rendere SGML indipendente dalla piattaforma hardware e software definendo attraverso un nome tutti quei caratteri che possono causare problemi. Questo vale per tutte le lettere accentate e quei simboli che a volte vengono ottenuti con difficoltŕ con la tastiera che si dispone, o che non possono essere ottenuti con il tipo di codifica (ASCII) utilizzato. In pratica, questo fa si che di solito la lettera ``ŕ'' possa essere identificata attraverso la macro à, la lettera ``č'' sia identificata da è, ecc.
In SGML una macro di questo tipo viene definita come entitŕ o entity e gran parte della codifica che riguarda lettere accentate e simboli speciali č giŕ standardizzata.
Per definire il DTD e anche le entitŕ, si utilizzano delle istruzioni che convenzionalmente sono delimitate da <! e >.
Un sorgente SGML inizia normalmente con la dichiarazione del tipo di DTD utilizzato. Puň trattarsi di un file esterno o di dichiarazioni incorporate nel documento stesso.
Per esempio, la dichiarazione seguente indica all'analizzatore SGML di utilizzare un DTD esterno denominato linuxdoc.
<!doctype linuxdoc system>
L'esempio seguente mostra invece una dichiarazione iniziale che contiene le istruzioni che compongono il DTD.
<!doctype personale [
...
-- istruzioni SGML --
...
...
]>
Una terza possibilitŕ permette di definire un file esterno e di aggiungere altre istruzioni particolari riferite al documento, come nell'esempio seguente.
<!doctype linuxdoc system [
...
-- istruzioni SGML --
...
...
]>
Dal punto di vista di SGML, una singola unitŕ di testo, la cui dimensione varia a seconda del contesto, č un elemento e a ognuno di questi, SGML impone l'attribuzione di un nome. SGML non fornisce alcun modo per attribuire un significato agli elementi del testo, tranne per il fatto di avergli dato un nome, piuttosto, verifica che questi siano collocati correttamente secondo le relazioni stabilite.
Nel sorgente SGML, gli elementi sono normalmente indicati attraverso l'uso di tag che hanno la forma consueta <...> e </...>, dove il primo inizia l'elemento nominato tra le parentesi angolari e il secondo chiude l'elemento. Per esempio, si potrebbe definire l'elemento grassetto e utilizzarlo nel modo seguente.
...Questa azione <grassetto>non puň</grassetto> essere compiuta ...
Nel DTD, gli elementi vengono dichiarati utilizzando l'istruzione element. Nel caso dell'esempio appena visto, il ``grassetto'' potrebbe essere dichiarato nel modo seguente.
<!element grassetto - - (#PCDATA) >
L'istruzione inizia con il simbolo <! seguito dalla parola element e si conclude con il simbolo >. All'interno, la prima cosa a essere indicata č il nome, o il gruppo di nomi, di entitŕ che vengono dichiarati; quindi seguono due caratteri che identificano le regole di minimizzazione; quindi segue il modello del contenuto. Gli elementi contenuti in una dichiarazione di questo tipo, sono separati da spazi, tabulazioni o simboli di newline, ciň significa che si puň suddividere su piů righe.
Le regole di minimizzazione, rappresentate nell'esempio da due trattini staccati, indicano l'obbligatorietŕ o meno dell'utilizzo del marcatore di apertura e/o di chiusura per l'elemento dichiarato. Il primo dei due simboli rappresenta l'apertura, il secondo la chiusura. Un trattino indica che il marcatore č obbligatorio, mentre la lettera o sta per ``opzionale'' e indica cosě che puň essere omesso.
- - sono obbligatori entrambi i marcatori;- o č obbligatorio il marcatore iniziale, mentre quello finale č
facoltativo;- il marcatore iniziale č facoltativo, mentre quello finale č
obbligatorio (di solito non capita mai questa situazione);
L'ultima parte della dichiarazione č posta tra parentesi tonde e descrive il tipo di contenuto che puň avere l'elemento. Nell'esempio precedente č stata usata la parola riservata #PCDATA che sta a indicare un qualunque tipo di dati in formato carattere.
Il modello del contenuto viene usato soprattutto per definire quali altri tipi di elementi possono essere contenuti, in modo da escludere tutti gli altri.
<!element itemize - - (item+) >
<!element enum - - (item+) >
<!element item - o (#PCDATA) >
Nell'esempio, si vedono le istruzioni di dichiarazione di tre elementi. Le prime due possono contenere l'elemento item e questo puň contenere qualunque carattere.
Il modello del contenuto utilizza un sistema abbastanza complesso per definire la possibilitŕ di contenere piů elementi dello stesso tipo e per indicare raggruppamenti di elementi.
Nell'esempio visto sopra, l'elemento item poteva essere utilizzato una o piů volte.
Il modello del contenuto puň fare riferimento a un gruppo di elementi, e in tal caso, si utilizzano dei simboli, o connettori di gruppo.
<!element descrip - - (tag?, p+)+ >
L'elemento descrip puň contenere una o piů ripetizioni del gruppo (tag?, p+), che a sua volta puň essere composto da zero o un elemento tag e da uno o piů elementi p.
---------
<!element figure - - ( (eps | ph), img*, caption?) >
L'elemento figure deve contenere una occorrenza del gruppo ( (eps | ph), img*, caption?), cioč una occorrenza del sottogruppo (eps | ph), zero o piů ripetizioni dell'elemento img e al massimo una occorrenza di caption. Il sottogruppo (eps | ph) rappresenta una occorrenza di eps oppure ph.
Se nella definizione di un elemento si vogliono indicare delle eccezioni a quanto definito dal modello di contenuto, si puň; indicare un gruppo di elementi successivo al modello del contenuto.
Questo gruppo puň essere preceduto dal segno + o dal segno
- indicando rispettivamente una eccezione di inclusione, o una eccezione di
esclusione.
<!element address - o (#pcdata) +(newline) >
L'elemento address contiene caratteri normali, ma puň includere in particolare anche l'elemento newline.
<!element grassetto - - (#pcdata) -(grassetto) >
L'elemento grassetto contiene caratteri normali e non puň includere se stesso.
Alcuni tipi di elementi non sono fatti per circoscrivere una zona di testo, ma solo per rappresentare qualcosa che si trova in un certo punto. Questi elementi, non vengono dichiarati con un modello di contenuto tra parentesi, ma con l'utilizzo della parola chiave empty.
L'esempio seguente, dichiara l'elemento toc che non puň contenere alcunché.
<!element toc - o empty>
Un marcatore utilizzato nel sorgente SGML puň contenere a volte l'indicazione di attributi. Il classico esempio č costituito da quei marcatori utilizzati per i riferimenti incrociati. L'esempio seguente mostra la dichiarazione dell'elemento ref che si intende utilizzare come riferimento a una parte del documento identificata attraverso il valore attribuito all'attributo id.
<!element ref - o empty>
<!attlist ref
id cdata #required
name cdata "riferimento" >
Attraverso l'istruzione attlist si definiscono gli attributi di un elemento. Dopo l'indicazione del nome dell'elemento a cui si fa riferimento, segue l'elenco degli attributi, ognuno dei quali inizia con un carattere newline seguito eventualmente da altri tipi di spazi. Ciň significa, che l'istruzione attlist deve essere composta proprio come indicato dall'esempio, solo i rientri sono facoltativi.
L'esempio indica che l'elemento ref č composto da due elementi: id e name. Il primo č obbligatorio (#required), mentre per il secondo č stato indicato un valore predefinito, nel caso non venga utilizzato (riferimento).
Il tipo di contenuto i un attributo viene definito attraverso delle parole chiave:
Il tipo di contenuto puň essere indicato in modo preciso attraverso una serie di scelte alternative. In tal caso, invece di utilizzare le parole chiave giŕ elencate, si indicano le stringhe alternative, separate dalla barra verticale, tra parentesi tonde. Per esempio, (bozza | finale) rappresenta la possibile scelta tra le due parole bozza e finale.
L'ultimo dato da inserire per ogni attributo č il valore predefinito, oppure una parola chiave a scelta tra le seguenti:
Con questo termine si fa riferimento a due tipi di oggetti: macro per la sostituzione di stringhe (general entities) o macro per la sostituzione di nomi all'interno di istruzioni SGML (parameter entities).
Le macro per la sostituzione di stringhe, una volta dichiarate, si utilizzano all'interno del sorgente SGML come abbreviazioni o come un modo per identificare lettere o simboli che non possono essere usati altrimenti. Per esempio, utilizzando le entitŕ ISO 8879:1986, la frase
Wer bekommt das größte Stück Torte?
puň essere scritta nel sorgente nel modo seguente.
Wer bekommt das größte Stück Torte?
L'altro tipo di macro, riguarda invece la sostituzione all'interno delle istruzioni SGML, di solito viene quindi usato nel DTD.
L'esempio seguente mostra la dichiarazione dell'elemento p che puň contenere l'elemento o gli elementi indicati all'interno della macro inline.
<!element p - o (%inline;) >
La dichiarazione di una entitŕ avviene utilizzando l'istruzione entity. L'esempio seguente mostra la dichiarazione di una entitŕ da utilizzare nel sorgente SGML.
<!entity agrave "\`a">
In questo caso, si vuole che la macro ``à'' venga sostituita con la stringa \`a. Evidentemente, questa trasformazione non ha niente a che vedere con SGML. Č semplicemente una scelta motivata evidentemente dal tipo di programma utilizzato successivamente per rielaborare il risultato dell'elaborazione dell'analizzatore SGML.
L'esempio seguente mostra la dichiarazione di due entitŕ da utilizzare all'interno delle istruzioni SGML.
<!entity % emph " em | it | sf | sl | tt | cparam " >
<!entity % inline "(#pcdata | %emph;)*" >
La dichiarazione di questo tipo di entitŕ si distingue perché viene utilizzato il simbolo di percentuale subito dopo la parola entity. Anche in questo caso si utilizza solo come pura sostituzione di stringhe, per cui la dichiarazione di inline, facendo a sua volta riferimento a emph, č equivalente a quella seguente.
<!entity % inline "(#pcdata | em | it | sf | sl | tt | cparam )*" >
In precedenza era stata vista la dichiarazione dell'elemento p utilizzano un riferimento alla macro #inline. Quella dichiarazione č equivalente alla seguente.
<!element p - o ((#pcdata | em | it | sf | sl | tt | cparam )*) >
Le entitŕ (di qualunque tipo) possono essere acquisite da un file esterno al DTD, e questa č una tecnica normale. In tal caso, si utilizza la parola chiave system come nell'esempio seguente.
<!entity % isoent system>
%isoent;
L'esempio mostra la dichiarazione della macro %isoent; e subito dopo il suo utilizzo. In pratica si ha l'inserimento del contenuto del file isoent nel punto in cui si fa riferimento alla macro %isoent; che di fatto lo contiene.
All'inizio di questa serie di sezioni si č visto in che modo inizia un sorgente SGML. Il tipo di documento deve essere stato dichiarato nel DTD, anche se puň sembrare ridondante. In effetti č necessario dire di cosa č composto il documento. Nel DTD potrebbe apparire una istruzione come quella seguente.
<!element linuxdoc o o ( article | report | book | letter ) >
In questo esempio, si comprende che non č necessario usare marcatori del tipo <linuxdoc> </linuxdoc> per delimitare il sorgente SGML. Infatti, la coppia di ``o'' afferma che queste sono opzionali. Invece, il tipo di documento linuxdoc deve contenere esattamente un elemento del tipo article, oppure report, oppure book, o ancora letter.
Il sorgente SGML che fa riferimento al tipo di documento linuxdoc e che utilizza il formato definito dall'elemento article, sarŕ composto schematicamente come segue.
<!doctype linuxdoc system>
<article>
...
...
...
</article>
Un tipo di documento potrebbe essere definito in maniera diversa, per esempio nel modo seguente.
<!element miodoc - - ( sezione+ ) >
In questo caso, il documento puň contenere solo elementi sezione ed č obbligatorio l'utilizzo dei marcatori per indicare l'inizio e la fine del tipo di documento.
<!doctype miodoc system>
<miodoc>
<sezione>
...
...
...
</miodoc>
Per convenzione, i nomi di entitŕ sono sensibili alla differenza tra lettere maiuscole e minuscole, per cui À e à rappresentano rispettivamente la lettera ``A'' maiuscola con accento grave e la ``a'' minuscola con accento grave.
Per convenzione, i nomi degli elementi non sono sensibili alla differenza tra lettere maiuscole e minuscole.
Il sistema standard utilizzato per la documentazione di Linux č basato su SGML-Tools. Questo pacchetto SGML non č particolarmente sofisticato, ma ha il vantaggio di essere giŕ dotato di un DTD e di un sistema di script che gli permette di convertire il sorgente SGML nei formati piů comuni: LaTeX, HTML e testo normale.
SGML-tools č in corso di trasformazione e attualmente sono disponibili diversi DTD per mantenere la compatibilitŕ con i documenti prodotti in precedenza.
Dal momento che SGML-tools utilizza fondamentalmente LaTeX per produrre documenti stampati, Č necessario avere a disposizione anche quest'ultimo pacchetto.
La struttura di un sorgente di SGML-tools dipende naturalmente dal tipo di DTD, ma in generale si utilizza questa convenzione.
<!doctype linuxdoc system>
<article>
<titlepag>
<title>Titolo del documento</title>
<author>Pinco Pallino ppallino@topolino.zigozago.dg</author>
<date>31/12/1999</date>
<abstract>
Breve introduzione al documento.
</abstract>
</titlepag>
<toc>
<sect>Prima sezione
<p>
Contenuto della prima sezione,
...
...
(eventuali altre sezioni)
</article>
Dalla istruzione <!doctype linuxdoc system> si afferma di voler utilizzare il DTD linuxdoc.
Il documento č delimitato dall'entitŕ article che rappresenta uno tra diversi tipi di struttura possibile del documento. Il DTD linuxdoc č derivato dal QWERTZ che era strutturato in modo da imitare il comportamento di LaTeX. In questo modo, nel DTD originale erano previste diverse strutture, tutte riferite ad analoghi tipi di documento LaTeX. La tendenza generale č quella di utilizzare sempre solo la struttura article, soprattutto perché, lo scopo di SGML-tools č quello di permettere la trasformazione del sorgente SGML in un grande numero di altri formati, e non solo LaTeX.
Dopo l'inserimento dell'entitŕ title, e di tutto ciň che deve contenere (titolo, autore, descrizione del documento), č possibile inserire <toc> con il quale si intende inserire un indice del contenuto.
Dopo l'indice del contenuto, inizia il testo del documento, suddiviso in sezioni: >sect>, >sect1>, >sect2>, >sect3> e >sect4>.
1997.10.26 - Scritto da Daniele Giacomini daniele@calion.com (vedi copyright: Appunti Linux).